
Note: This is an SSRN Pre-Print version of the article.
Abstract
The emergence of Large Language Models (LLMs) in legal research signifies a transformative shift. This article critically evaluates the advent and fine-tuning of Law-Specific LLMs, such as those offered by Casetext, Westlaw, and Lexis. Unlike generalized models, these specialized LLMs draw from databases enriched with authoritative legal resources, ensuring accuracy and relevance. The article highlights the importance of advanced prompting techniques and the innovative utilization of embeddings and vector databases, which enable semantic searching, a critical aspect in retrieving nuanced legal information. Furthermore, the article addresses the ‘Black Box Problem’ and explores remedies for transparency. It also discusses the potential of crowdsourcing secondary materials as a means to democratize legal knowledge. In conclusion, this article emphasizes that Law-Specific LLMs, with proper development and ethical considerations, can revolutionize legal research and practice, while calling for active engagement from the legal community in shaping this emerging technology.
I. Introduction
II. The Terminology Problem and Law-Specific LLMs
A. Advanced Prompting
B. Embeddings and Vector Databases
C. Sourcing
III. The Black Box Problem, Remedies, and the Future
A. The Black Box Problem and Remedies
B. Crowd-sourcing Secondary Materials
C. Fabricating Secondary Materials
IV. Conclusion
Introduction
As the legal landscape evolves, the integration of technology in research practices is becoming increasingly indispensable. This article delves into Large Language Models (“LLMs”) and their transformative impact on legal research, elucidating how they streamline processes, improve accuracy, and enable legal professionals to allocate their resources more efficiently.
Let’s dive into the topic at the most controversial place: Hallucinations. Hallucinations are at the forefront of everyone’s mind when they are using these tools for legal research. It’s important to address the concerns that many people justifiably have when thinking about whether these tools can have any lasting impact on our field. The first thing to note is that hallucinations result from a poorly tuned or optimized model, and occur when there is too much “noise,” which is a term used to describe a model that is either too large or not fit for the purpose that the user is employing. In the context of legal research, this has been seen in the headlines, and even in Federal court cases, where ChatGPT has created completely false or otherwise misleading case law citations.[1] ChatGPT also hallucinates on a wide range of different issues, which makes law librarians hesitant to use it for serious and technical applications such as legal research.
This is a very reasonable concern. We are dealing with research that can cause people to lose their life savings or even land people in prison for the rest of their lives. The stakes couldn’t be higher – reliability and precision are crucial. This is what we teach our students during legal research classes, and that’s why we point them towards high-quality resources, like treatises and practice guides with immaculate editorial standards. I want you to understand that I take these concerns seriously and hopefully, this will allow you to have some peace of mind if you choose to use these tools instead of typical keyword searches.
Law-Specific Large Language Models, when intricately tailored through advanced prompting and embeddings, hold the potential to revolutionize legal research; however, addressing the Black Box Problem and exploring innovative sourcing strategies are imperative to ensuring the transparency, reliability, and democratic dissemination of legal information.
_____________________
[1] Benjamin Weiser, Here’s What Happens When Your Lawyer Uses ChatGPT, NYT (May 27, 2023), https://www.nytimes.com/2023/05/27/nyregion/avianca-airline-lawsuit-chatgpt.html
The Terminology Problem and Law-Specific LLMs
ChatGPT, as a generalized large language model, exhibits several inherent limitations that impede its efficacy in legal research. The first issue lies in the broad scope of its knowledge base. ChatGPT is designed to cater to a wide array of queries from an assortment of domains and produce a huge range of outputs. While this versatility enables users to obtain preliminary information, it falls short in the context of legal research where specificity, precision, and reliability are paramount. In analogy, students are advised that Google searches might be a starting point for legal research, but should not be regarded as dispositive due to the varying quality of sources. Asking ChatGPT a legal research question is like Googling a research question and then cutting and pasting the summary of the first result into a legal research memo. It could be an excerpt from an attorney’s blog which is mostly correct, it could also be an ad for a product on Amazon. In either case, it is not how we conduct legal research.
Additionally, ChatGPT’s database encompasses a huge volume of information that produces “noise” unrelated to legal issues. This extraneous data can clutter the results, making it cumbersome to nearly impossible for the model to provide reliable legal answers because one of the trickiest aspects of a general-purpose LLM like ChatGPT is switching contexts between different specialized fields. Sometimes it can pull this off but other times it is pulling from a wide range of sources that have nothing to do with the law.
In stark contrast to generalized models like ChatGPT, subject-specific LLMs such as Casetext’s Cocounsel,[2] Westlaw AI,[3] and Lexis AI[4] offer a more tailored approach that is ideally suited for legal research. These LLMs are built upon specialized databases that are enriched with high-caliber legal resources. The meticulous curation of content ensures that researchers have access to a relevant and authoritative information repository. It also reduces the noise around legal terms of art and law-specific vocabularies. As we all know, Lexis and Thomson Reuters are not suddenly going to make their high-quality secondary materials freely available, since they can charge us hundreds of thousands of dollars each year to subscribe to them.[5] Without those to train the models, or some really clever, law-specific prompting and retrievers (more below), even models that are connected to case law databases are lacking the foundational information that they need to easily provide good answers to legal research questions. A good secondary source tells you “the law,” the history of the law, and gives you valuable insights from practitioners in that area of law. It is updated constantly and has immaculate editorial standards. The single step of training the data on a smaller number of highly relevant resources dramatically reduces hallucinations. It no longer pulls from random websites like Reddit and other blogs, which could provide confusing feedback or unsophisticated information.
In addition, the software engineers and attorneys at places like Lexis and Westlaw will fine-tune these LLMs so that they are narrowly focused on providing answers to the legal community. Consequently, users can conduct in-depth research with a higher degree of accuracy and confidence, knowing that the information yielded by these specialized LLMs aligns with the rigorous standards expected in legal scholarship and practice. This explains the willingness of platforms like Lexis, Westlaw, and Casetext to dive headfirst into this technology (remember, most people became familiar with ChatGPT in about February of this year and it’s already being implemented). They know that they can make law-specific LLMs highly accurate and highly useful, even in the prototype form that we currently have available. If you are still not convinced or impressed by this technology, just give it time and you will be.
_____________________
[2] Casetext’s Cocounsel (which has been recently acquired by Thomson Reuters) https://casetext.com/cocounsel/
[3] Generative AI is coming to Westlaw Precision, https://legal-thomsonreuters-com.ezproxy1.lib.asu.edu/en/c/westlaw/generative-artificial-intelligence-upgrade
[4] Lexis+ AI https://www.lexisnexis.com/en-us/products/lexis-plus-ai.page
[5] Andrea Keckley, Law Librarians Play Key Tech Role With Pinched Budgets, Law360 (May 5, 2023) https://www.law360.com/pulse/articles/1604344/law-librarians-play-key-tech-role-with-pinched-budgets
Advanced Prompting
A concept that is often not understood to its full extent is “prompting.” When we talk about promoting, in general, we usually mean providing the model with some context so it knows what type of information to look for. The more context that you provide to the LLM in the prompt the more the model can predict information that has similar patterns and concepts. You’ve probably seen something like this for legal prompting:
You are a law professor at a top united states law school. You are an expert in Administrative Law and provide all of your output in a clear, academic tone without bias. Please summarize the current state of the Chevron Doctrine in ten bullet points.”
That is not what I’m talking about. LLMs need help comprehending a given situation’s specific context and nuance, making it difficult for them to provide relevant and appropriate responses. This can result in significant miscommunication or misinformation, especially in the case of technical, subject-specific research. LLM-specific programming languages and software packages like LlamaIndex and Langchain allow for the creation of complex behind-the-scenes prompts, sometimes with dozens of steps (or “multi-stage reasoning”) that provide natural language feedback to the LLM before the user ever sees a response.[6] They can change the way that the LLM is gathering data for search and retrieval and limit the pool of available responses to only certain areas of certain databases.

[6] LlamaIndex, https://huggingface.co/llamaindex
Langchain Documentation, https://docs.langchain.com/docs/
There are also simplified versions of advanced prompting available like Microsoft Guidance, https://github.com/microsoft/guidance and GUI interfaces like FlowiseAI, https://github.com/FlowiseAI/Flowise and Langflow, https://github.com/logspace-ai/langflow
A. Natural Language Conceptual Examples:[7]
User query:
“I’d like to find a California state court case from 2023 about an eviction at a hotdog stand.”
- Create {user-prompt} to store the user query.
Behind the Scenes
Router Chain
{user-prompt} is looking for cases → {Prompt-C}
Prompt-C Workflow
Search [Dockets API] and retrieve cases with facts similar to {user-prompt}
- Create {case} to store the results.
- If no cases with similar facts state, “No cases found.”
- (Failover logic)
Format the {case} with a URL hyperlink directly to the case in [Dockets API] according to {Bluebook-prompt} (a separate prompt that formats the output according to the Bluebook)
- Create {formatted-case} to store the results.
Create a one-paragraph summary of the {case} as it relates to {user-prompt}
- Create {description} to store the results.
Prompt-C Output
- Format output as a list:
- {formatted-case}
- {description}
Example output
- (“Few shot prompting” – You would include samples for it to learn and emulate)
- Smith v. Jones, 23 Cal. App. 45 (1982). In this case the defendant leased the space for a hotdog stand on the corner of Santa Monica Blvd and Ocean Ave from a commercial real estate company. The company canceled the lease and evicted him because he breached the lease by selling hamburgers instead of hotdogs.
This is a very simplified example of the types of things that could be done with something like Langchain and access to a dockets API. You’re not creating a single prompt but tons of multi-stage reasoning prompts that nudge the model to do exactly what you want it to do. Langchain is particularly innovative because it is not as complex as coding in Python or similar languages. It was specifically designed to be a simpler language, enabling even those without extensive technical expertise to create sophisticated prompts. It makes these tools extremely useful, especially for law librarians who have some background in coding languages like HTML, R, Python, or JS. In the examples, I have included the query so that it’s easier to understand the logic, but these prompts can be injected into the model before the user sees anything, allowing them to communicate with the model like a regular chatbot while all of this goes on in the background. This is also why a subject-specific model for legal research would be substantially more useful than something like ChatGPT. A company like Lexis or Westlaw could add layers and layers of legal research prompts behind the scenes.
Even in this example, I have perhaps simplified the process down to a facile version of what they are doing. You can chain these prompts in ways that feel akin to magic, changing the output to different formats, double and triple-checking output, running several similar searches and synthesizing results, and even sending the output to other applications and services to make use of it (send it in an email, put it into a database for storage, etc.). You could have a massive library of detailed prompts for every niche task. Casetext’s Cocounsel is doing something along these lines when you ask it to create a Research Report. It is not submitting a single query to a database. It is running tons of these logic-based prompts with checks and analysis in the background and then combines and summarizes the results. It is doing the equivalent of hours’ worth of research by a team of researchers… in minutes (or sometimes even seconds).
This is especially useful when you have good data. The entry of legal research giants, Lexis and Westlaw, into the artificial intelligence arena heralds a seismic shift in the methodologies underpinning legal research. You can layer these complicated prompts and then leverage them to find top-tier secondary materials that are published by Thomson Reuters and Lexis. The Lexis AI that I demoed accepted the context of a legal research question (or case documents) to find: a practice guide section on the topic, a jurisdiction-specific legal encyclopedia article, and a practical law note. Westlaw acquiring Casetext is similarly exciting: you have Casetext bringing technical machine learning experience and Westlaw’s famously stellar publications to make a highly sophisticated, high-quality LLM specifically for law.
I’m not advocating that every law librarian should immediately enroll in Computer Science classes to learn new programming languages. Frankly, you don’t need to in order to use these tools. However, having someone on your staff with a basic understanding of these processes could become very valuable and could provide a new form of outreach (and growth) for your law library. Being at the nexus of information science and law means that most of us have people on our staff who understand these concepts and processes better than the vast majority of the law school ecosystem.
Embeddings and Vector Databases
Imagine you have a vast collection of books and you want to create a magical card catalog or index where you can instantly find not just books, but also ideas and concepts that are similar or related. Embeddings in Large Language Models (LLMs) are like creating this magical index.
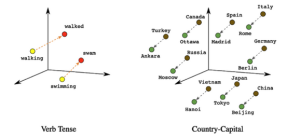
In this index, each book, paragraph, or even word is represented by a magical token. These tokens are arranged in such a way that similar ideas and concepts are placed closer together. For instance, tokens representing books about dogs would be near tokens representing books about puppies, while tokens for science fiction novels would be in a different corner. Vector embeddings map three-dimensional relationships between all chunks of data (words, letters, sentences, tokens – your choice) and create quantifiable relationships between them. These embeddings are the underlying technology that makes the predictive nature of LLMs so powerful because it allows for semantic searching.
Semantic searching is like a superpower for researchers. This allows you to figure out not only how different keywords are similar to each other but also how different expressions and concepts, that have nothing in common in vocabulary, can be similar. For example, consider the phrases:
- “the cat meowed for food”
- “the kitten called for treats”
These two expressions would be very difficult to connect through a traditional keyword search but conceptually they are similar. However, once you have embeddings in place, the terms are close enough to pick up this nuance easily. The ability to search for similar vectors cannot be emphasized enough. It creates a whole new world of possibilities that are not available if you must write code that is constrained by the rules of things matching exactly (like searching for an exact keyword.)
Imagine the complexity of some of the Boolean expressions you’ve created for complex legal scenarios that contain multiple synonyms or similar situations. In this example, we are searching for [Prompt] a DUI driving arrest where the person was stopped on the side of the road, keys in the ignition but the engine is not running.
(drunk driving OR intoxicated OR under influence OR impaired OR alcohol OR drug OR substance abuse OR alcohol abuse OR drug abuse OR DUI OR DWI)
AND
(NOT (car started OR vehicle started OR ignition started OR engine started))
With embeddings, the search could be queried using natural language terms – something as simple as the italicized [Prompt] text above. Additionally, the relationships created in a vector database are especially useful to a field that frequently relies on analogy to craft compelling arguments. A popular law school assignment for basic legal research and writing is the (now tired) “dog bite” hypothetical. There is a statute with liability for dog bites and then the professor replaces the dog with another type of animal so that the student has to analogize and be creative in crafting search terms. These tools would likely easily find that connection in the relevant case law with vector embeddings. In this way, legal research is especially well-suited to the use of LLMs in ways that other fields are not. Much of it is based on words and similar concepts
How this works practically in a diagram[8]
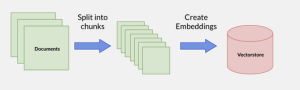
When using an LLM specifically for legal research, the data could be indexed on something what is called a vector database (or vector store). This is typically a separate step in the process so that the LLM is not querying the underlying information or embeddings directly. Let’s discuss vector databases for a moment because they are like metadata on steroids. We are accustomed to keyword searching with Boolean expressions to query the equivalent of large SQL databases. When you’re calling large piles of documents (imagine all of your internal documents for work or all of the federal cases in the US), it is fairly common nowadays to use a vector database. This is very important when you are dealing with a huge amount of information and need a way to quantify and summarize it. This technology has been around for a while and is already being used in many places you visit on the internet (for example, Amazon.com[9]. Popular applications currently for LLMs are databases line Pinecone.io and Weaviate.io.[10]
Once that process is over, you don’t even need a separate search algorithm to query this data because the relationships are already in the vector database. These relationships can then be compressed with Product Quantization so that they are fewer bytes (smaller) and can be queried quickly.
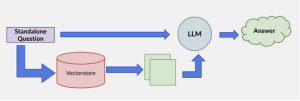
How this works practically in a diagram[11]
Sourcing
One of the biggest problems with ChatGPT is the output that you receive gives you no indication of where the underlying prediction came from. Microsoft Bing is an excellent example to consider. It provides hyperlinks to sources at the bottom of every answer it gives. This is in stark contrast to chatbots like ChatGPT and Claude+, which typically generate responses without providing sources. While ChatGPT can be a useful tool, it doesn’t give users a way to delve deeper into the information or even confirm if the sources are real (without the help of plugins).
In the legal domain, it is imperative that any information provided by a large language model is verifiable and backed by authoritative sources. Lawyers and legal researchers must be able to read and analyze the cases being cited to ensure accuracy and relevance. Hence, a legal-specific language model should (and would in the examples I’ve seen from Casetext, Westlaw, and Lexis) not only provide answers but also include hyperlinks to the cases and sources it references. This allows users to click and review the original documents to determine the accuracy of the information, which is crucial for how we would use the models. It is another instance where you see a general LLM being much less useful in a legal setting and, hopefully, helps illustrate how powerful industry-specific LLMs could be for us. All of the law-specific LLMs are those that I have demo’ed, trailed or used. I have created my own to work with but they’re not commercially available. I have allowed you to see the source of the information you receive as output for search and retrieval. Generative AI is a whole different can of worms because there are no underlying source documents that the LLM could provide. It is assembling sentences token by token and pulling from a wide range of sources.
The Black Box Problem and Remedies
However, like many algorithms, this process is often seen as a black box, which can be frustrating. The pre-training of data and reinforced learning is not necessarily transparent depending on the model, which is similar to how Lexis and Westlaw operated their search algorithms. We have an inkling that this will be the case because both Westlaw and Lexis are building on OpenAI’s GPT models and we have not had open-source access since GPT4 came out.[12] Casetext uses a self-hosted version of GPT4 on its own servers to run Cocounsel.[13] In all these instances, prompting and training could be like their current search algorithms (a “secret sauce” where they do not want to release the recipe). If we see some movement on AI regulation, we may get something similar to the open-source models that are available on Huggingface where we can see a Github-like record of changes and evaluate individual actions and review the files.
The crucial request that we can make is that services like Casetext give us a record of the steps that their prompting has completed. This is important so we can catch blind spots and don’t duplicate efforts. If they won’t give us the underlying prompt code, we may be able to convince them to at least give us a summary of the steps. While law students and attorneys may be content to take the results and run with them, it seems unlikely to me that law librarians (who are frequently tasked with the most difficult, nuanced legal research projects) will be satisfied.
Additionally, we can advocate that they give us API access to the models or their vector databases. This could be a game-changer! It enables tech-savvy librarians to connect to the platform and leverage advanced prompting techniques to extract the information. While it does not give full control (as the reinforcement mechanisms and pretraining remain hidden), it’s akin to mastering Boolean searches in the AI age… except you can do much more. The potential applications are virtually limitless, and you would have the Westlaw or Lexis database of high-quality materials as your playground.
Additionally, there are third-party options to evaluate the search and retrieval function of LLMs. Arize AI (just an example), runs inside your notebooks and will detect issues between distinct parts (in this instance between the vectoring database Pinecone and prompting language Langchain). Arize will allow you to see a 3D model of the chunks, prompts, and the response, in addition to how they relate to the vector embeddings so that you can see where your LLM is providing bad responses (again, this is specifically for search and retrieval). We could ask for these types of reports to evaluate the model in the same way that Cybersecurity teams ask for SOC2 reports. This is getting very deep into the computer science and data science aspects of LLMs but knowing what is going on and who you can turn to in your organization to fulfill this role is going to be a crucial decision for law libraries as we look toward the future of AI in legal research. Especially in an AI ecosystem where there is no settled leader (despite what GPT4 fans say), we need to be able to evaluate these ourselves and find the right model, embeddings, and prompts for each job.
Crowd Sourcing Secondary Materials
One massive problem with this type of LLM is that you are still relying on Westlaw and Lexis for their extremely expensive secondary materials to be the high-quality data that you train your models on. A potential workaround for this is crowd sourcing legal expertise. The original ChatGPT did something similar when they trained their data on Reddit. They leveraged a massive database of user-generated content that is freely available on the web. Similarly, we have seen some of the computer science LLMs train their data on Stack Exchange and Stack Overflow. There are already legal datasets available publicly on HuggingFace and Github to train models and find answers.
An interesting concept that we may see in the future is a sort of Law-Specific version of Wikipedia + Reddit, where attorneys could submit their own practice guides, legal encyclopedias, and practical law notes, which could then be brought into open-source models. There are some sites that already do this to a degree (Quora, Avvo, etc.) but these follow the Q&A format of the old Yahoo Answers, they’re not attempting to replicate something like a Practice Guide. The community would vote on the best resources and the model would be tuned to prefer those answers. Obviously, this has some drawbacks: quality could vary dramatically, updates could be erratic, bias could infect many answers, etc. It would undoubtedly require heavy-handed moderation from a team of legally sophisticated moderators. Even then, the quality would be lower than Lexis AI and Westlaw AI but it would be open source and it would cut into the duopoly created by these two publishers, allowing for competition and democratization of legal information.
Fabricating Secondary Materials
Sophisticated data scientists have been able to overcome this obstacle in other fields (medicine, for example) by scraping source documents and then fabricating training datasets for the LLM.[14] For law, it could look like this: you collect all the relevant legal data, run a complicated prompt over the documents to extract the information, collect that data into a training set, and then extract the useful information with another complicated prompt.
For a less abstract example, let’s say you take all of the publicly available cases from Harvard’s Case Law related to copyright law. You create embeddings for the entire text of all of the cases. Then you take a prompt that says something like, “collect the text of all of the judicial opinions that relate to fair use in copyright law.” Then you have another prompt that says, “What is the standard for analysis on fair use? What statute do they rely on for that analysis? What factors are used in their decision-making? Do they explain the history of fair use in copyright? Limit this request to only the cases that give a thorough analysis of fair use.” You essentially ask all of the questions one would need to create a legal encyclopedia article on the topic since judges routinely summarize the state of the law in the early part of opinions. You then take the output created by those prompts, chunk it up, and that is your training data for the topic of Copyright > Fair Use. Finally, you run another complex prompt on that training data to summarize and synthesize the law. You have now fabricated a legal encyclopedia article. You do that across all topics a legal encyclopedia would cover.
The way that this is traditionally done is to create a Teacher/Student paradigm with the LLM, where the user asks questions and teases out the information that they would need to add to the dataset. Once that dataset is complete, you have the refined, high-quality information you would use as a sort of manufactured legal encyclopedia to train the model. This is an area ripe for law librarians to help proprietary LLM’s learn how to answer unique and complex questions associated with legal research.
What was once an insurmountable task is now within the realm of possibilities with this technology. It is also a process that could be reused and refined as updates and new datasets became available. Obviously, there are substantial problems and barriers that you can think of but, at a bare minimum, it should give you an idea of the capabilities. In addition, we are not limited to “small” datasets like Harvard’s Case.Law database for this analysis. Massive, open-source legal datasets are already available (e.g. pile-of-law[9]) that have everything from regulations to state codes, to congressional hearings, to Reddit’s “legal advice” subreddit… and much, much more. It is only a matter of time before the open-source community begins to fabricate models that could compete with the traditional legal research hegemony.
Conclusion
LLMs excel in automating and speeding up repetitive and tedious processes, thereby significantly enhancing efficiency for mundane computer tasks. As it stands, you still need a thorough understanding of the law to evaluate the results you get back from any of these services. LLMs could afford law librarians the invaluable opportunity to allocate their time and energy toward more human-centric pursuits (the reference interview, 1-on-1 student appointments, teaching, writing, etc.). It also gives you some breathing room so you can spend time deeply reading (instead of skimming) and pondering the legal analysis and tasks before you. Finally, LLMs create new opportunities for law librarians to get involved in AI so that we can ride this tech tidal wave into the future and expand our budgets and staff. Noteworthy people in tech[10] have anticipated that the demand for legal services could increase in the AI age as questions surrounding ownership, usage, and risk become increasingly prescient. This reallocation of focus, facilitated by LLMs, not only optimizes the research process but also fosters a more interpersonal and service-oriented approach to law librarianship – specifically the part that is unlikely to be replaced by machines anytime soon.
* * *
[7] This is not the code, which would be difficult to read – only a high-level, English language diagram of the workflow you would be creating.
[8] From Sam Witteveen’s LLM Tutorial Github Repo, langchain-tutorials/YT_Chat_your_PDFs_Langchain_Template_for_creating.ipynb at main · samwit/langchain-tutorials · GitHub
[9] Dave Bergstein, Solving complex problems with vector databases, InfoWorld (March 8, 2022)
[10] Pinecone.io https://www.pinecone.io/, Weaviate https://weaviate.io/
[11] From Sam Witteveen’s LLM Tutorial Github Repo, langchain-tutorials/YT_Chat_your_PDFs_Langchain_Template_for_creating.ipynb at main · samwit/langchain-tutorials · GitHub
[12] Seth Kenlon, What does ChatGPT mean for the open source community?, Opensource.com (February 18, 2023) https://opensource.com/article/23/2/chatgpt-vs-community
[13] To the ambitious out there, you can already do this one your own home computer. Anthropic, the company behind Claude+, has a model that you can download and use for search and retrieval on your home PC. There are different options depending on how powerful your home PC (or Mac) is. In addition, it is private and does not release any of your information: https://gpt4all.io/index.html
[14] Pankaj Muthur, one of the developers behind the Orca LLM, was kind enough Zoom with me to explain to me how other fields have done this and so I would like to thank him for his time.
[15] Pile of Law, https://huggingface.co/datasets/pile-of-law/pile-of-law
[16] Reid Hoffman, Impromptu: Amplifying Our Humanity Through AI, Dallepedia LLC (2023)