
Beware the firm using “Big Data” to set fees

A recent flurry of Tweets reminded me that we still do a poor job of communicating why process improvement comes before Big Data (or small data) analytics in legal services delivery. Ever hopeful, I decided to take another stab at the topic.
The Customary Approach
We see stories from law firms announcing they will apply Big Data analytics to the history of fees they have charged for matters. The hope is that through statistical analysis of the data, they will find patterns that will guide them in setting future fees.
The premise sounds great. Assume a firm regularly handles middle-market corporate transactions. The firm goes to its time-keeping records and downloads all of the entries into a large file. Over the past five years the firm has handled 100 middle-market transactions. Now, through the wizardry of machine learning and natural language processing, it can mine that data. It can find patterns. For example, it could learn that the median time to draft the stock purchase agreement is 40 hours, with a standard deviation of 2.5. It can plot that data to get a distribution of time spent on drafting a stock purchase agreement. That distribution might look like this:
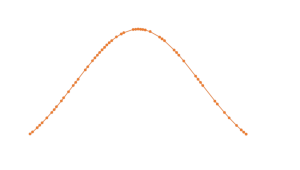 Big Data fee distribution before process improvement.
Big Data fee distribution before process improvement.
When the next middle-market deal comes along, the firm can evaluate the deal against the prototype middle-market deal and bid a price based on whether the new deal is above, below, or average. This sounds great — data at work.
The Not-So-Hidden Flaw
Let’s go back to those 100 transactions that make up the data set. Our first problem is the timekeeping entries. By process improvement standards, they are too coarse to use. We do not have a granular process map for preparing the stock purchase agreement (in fact, we do not know if the firm’s attorneys followed a standard process for preparing the document). We do not know the steps, the sequences, and the time spent on each step. Timekeeping entries — even detailed ones — do not provide anywhere near the data and granularity we need.
To understand what really happened during those 100 transactions, we need process maps and step-by-step data captures. To understand what this means, consider how many steps go into “drafting the stock purchase agreement.” In process improvement, we will look at each step and ask whether it adds waste or adds value. McKinsey & Co. estimates that 25% of steps in legal services delivery can be automated. Even casual studies of legal services delivery routinely show up to 50% of the steps are waste (my data comes in around 50%).
That means the timekeeping entries used in the data analysis provide a data distribution that is roughly 50% waste. Think of it as shifting the distribution to the right on the X axis to accommodate the waste
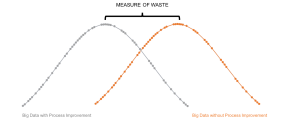
Big Data fee distribution comparing before and after process improvement.
The firm will quote fees based on its historical data, which includes lots of waste. The client pays for that waste. So, in reality, the client may pay a median price for an average deal, based on work that was 50% waste and 50% value. That is, the client is paying for a very inefficient process.
The Better Way
The problem with data analysis of processes that have not been improved creates ripples through the pricing system. There is a better way, and that means starting with the processes.
The firm should have mapped the processes (and there probably are many processes, given that no two lawyers work the same way) used to prepare the stock purchase agreement. The firm can then standardize on one process. Next, the firm can remove waste from the process (there are eight types of waste in lean thinking — and legal processes are drenched in these wastes).
With a waste-reduced standardized process, the firm can start by estimating the time it will take to prepare a draft stock purchase agreement using the new process (we can guess it will take 20 hours by assuming 50% of the prior process was waste). That should be the starting point for fee quotes. By collecting data on how long each step takes in the new process, the firm will generate a more accurate picture of the “cost” to prepare the agreement (assuming it calculates cost to the firm, not what it charges the client). From there, the firm could set a fixed fee (cost plus profit) and hope that market accepts the price. Or, it could charge based on time (which no client in its right mind should accept).
Mining Bad Data Is Not A Cure-All
Bad data is, well, bad data. Mining it does not make it better, it simply adds waste on waste. Think of all the things that go into timekeeping. One client wants entries phrased a certain way. Another does not like certain words. A third wants standardized entries. A fourth wants custom entries.
Timekeeping involves self-reporting, a notoriously inaccurate system. Timekeepers guess, the complete the entry forms well after the fact, and they don’t stare at the clock (I think that was about 3 hours).
Now ask what you really know about those 100 deals. What was exceptional about this one, unexceptional about that one? Was the draft stock purchase agreement unusual (and did your data mining adjust for that, and if so how?)? What process did the drafter follow — the “efficient” one or the “sloppy” one (assuming you can re-create either)? (For those of you who are budding data scientists, I’m asking if you normalized the data.)
Data has an unnatural allure. It is why lawyers are so tightly bound to the billable hour. It provides the illusion of certainty where no certainty exist. It seems like we have moved into the world of hard science because we use numbers, when in fact we have moved further away.
If you played sports, you may remember your coach telling you there were no shortcuts. You had to run laps, exercise, and drill to get better. If you learned to play an instrument, you heard a similar story. You have to practice skills, develop your technique, and go over the same piece of music again and again to get better.
Improving your craft is the same. You must study it, take it apart and put it back together, practice and perfect. Skipping ahead to “Big Data” doesn’t do it, it just covers a lack of work. Next time a firm says they set the fee using “Big Data,” ask to see their process maps, standard work, and metrics on time. If they can provide that information and it was the basis for the Big Data, you may be in good shape.
Editor’s Note: Published with permission of the author with first publication in Medium.