
As most people working in technology are aware, over the last few years “AI” has become an ever-present marketing buzzword. Machine learning is sold as a panacea, a sort of technological diet pill. Ingest some machine learning and your problem will be solved.
Yet for people building real world applications with machine learning, it has long been recognized that the Pareto Principle (informally known as the 80/20 rule) is alive and kicking. It’s pretty easy to use machine learning to build an 80% accurate solution, but getting into the mid 90s can be quite difficult. Reaching a 99% accurate solution is often impossible.
Fortunately, the gap between people’s perception of AI and reality is shrinking, as the limits of artificial intelligence get more public attention.
In a recent article appropriately titled Without Humans, Artificial Intelligence Is Still Pretty Stupid, the Wall Street Journal reported:
“[w]hile AI can take down 83% [of extremist YouTube posts] before a single human flags them, … the remaining 17% needs humans.”
According to the article, “Google doesn’t disclose how many people are looped into its content moderation, search optimization and other algorithms, but a company spokeswoman says the figure is in the thousands — and growing.”
Facebook, however, is disclosing its numbers. The article reports that Facebook currently employs 10,000 content moderators and is adding 10,000 more.
Google and Facebook are two of the leading AI companies in the world. Yet they still employ massive armies of people to do dull, rote tasks because their machine learning algorithms aren’t smart enough.
A few years ago such human-in-the-loop solutions were chided as insufficiently visionary. Today, there is a growing recognition that the AI-hype cart is far in front of the machine learning horse.
That leading companies are acknowledging they rely on people is great. But the discussion and knowledge around how these hybrid human-machine approaches work is lacking. This is an area where Judicata has considerable experience, so I thought I’d share our perspective.
One Size Doesn’t Fit All
At Judicata we spent five years “mapping the legal genome” — building a detailed understanding of the law that is unparalleled in its granularity and precision. Lawyers and clients have a lot on the line when they rely on our software and data, so accuracy is paramount.
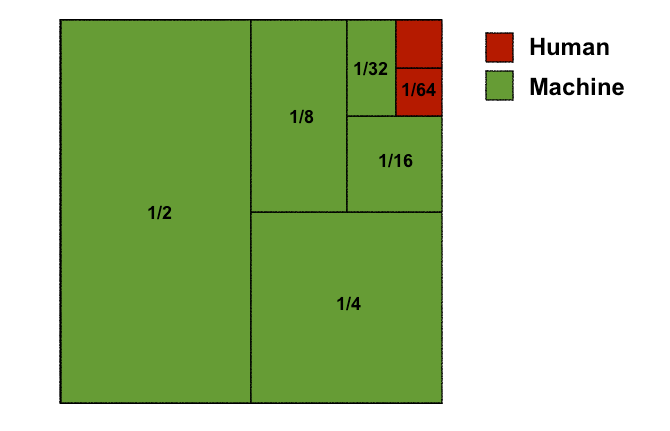
Because high accuracy matters, we use a hybrid human-machine approach when classifying data. This allows us to achieve higher accuracy than humans or machines can produce on their own, but at 5% of the cost of a fully manual system.
We rely on an iterative process for data development that we analogize to the infinite series, 1/2 + 1/4 + 1/8 + 1/16 + · · ·, the sum of which approaches 1.
The idea is that if we can repeatedly divide the unsolved portion of a problem into two halves — an easier half and a harder half — we can incrementally approach a 100% solution by repeatedly solving the easier halves.
A visual representation of the infinite series communicates this idea more clearly:
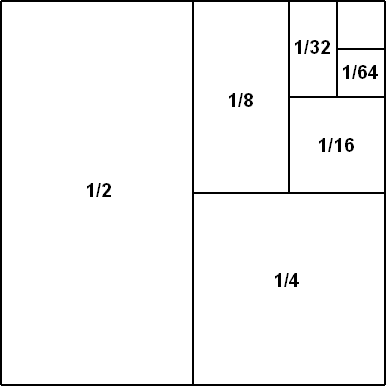
The total area of the image is 1, and the iterative approach involves first identifying and solving the ½ of the classification problem that is easiest, then identifying and solving the ¼ that is next easiest, then identifying and solving the ⅛ that is next easiest, and so on for as long as we find it worthwhile.
(The actual subdivision percentages are never perfect powers of ½, but the idea is the same.)
Note that the solution for any particular subdivision can be machine learning, domain specific code, or human review — whichever works best for the subdivision. But the great thing about having a human in the loop is that we can stop iterating on the technology and rely on a person whenever the problem gets too hard and the technology starts to fail.
Baseballs Are Round
Let’s contrast this with an overarching one-size-fits-all machine learning solution.
Machine learning algorithms are designed to identify and value the most distinguishing features — those whose presence or absence provides the algorithm with the most predictive power. For example, an algorithm tasked with identifying leopards may fixate on the distinctive shape and color of its spots.
The problem is that these algorithms are also lazy (by design). They do a poor job of learning less distinguishing features when the data doesn’t require them to.
For example, consider a machine learning algorithm that labeled the following images “baseball” and “starfish” (from this research paper):
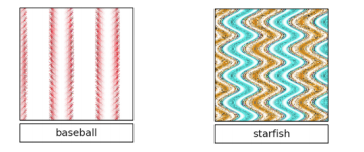
It’s easy to see that for “baseball” the algorithm learned to recognize the visual cue of red seams on a white background. For “starfish” the algorithm learned to recognize orange protrusions that taper to a point.
But the algorithm didn’t learn other important features such as baseballs are round, or starfish are shaped like a star:

It didn’t learn these features because it didn’t need to.
To relate this back to the Pareto principle, the infinite series, and our iterative process, the features that drive accuracy in the later iterations are less distinguishing than the features that drive accuracy in the earlier iterations. Doing well on the first ½ and ¼ subdivisions can be easy, but getting good results in the later subdivisions becomes increasingly difficult since machine learning algorithms are blind to the less distinguishing features.
Notably, trying to address the issue by adding more training data can be an uphill battle. It would take many images of square objects that look like baseballs for the algorithm to learn that baseballs are round. And it would take many more images with various other shapes for the algorithm to learn that starfish are shaped like stars.
In fact, the amount of data needed to train a machine learning algorithm grows exponentially with the number of features that the algorithm needs to learn. The training data needs to identify the impact of both the presence and absence of each relevant feature, and it needs to show how that feature interacts with every other relevant feature.
So if the number of relevant features is n, the algorithm can need 2^n training examples to learn each of the relevant features and how they interact with each other. Getting data at that scale quickly becomes prohibitively expensive.
Divide And Conquer
The iterative approach, on the other hand, is focused on repeatedly identifying the next most relevant feature and building a distinct classifier for it. This ultimately requires building n individual feature classifiers rather than a single overarching classifier. While this may seem like a step backward (especially in the world of unsupervised deep learning where the machines learn the features themselves), it is often a necessary step to getting higher accuracy.
Revisiting the baseball example from above, the iterative approach could involve building two different sub-classifiers: one to identify red seams on a white background and one to identify round objects. Requiring a match on both would lead to a much more accurate baseball classifier.
In addition to accuracy, there are several other advantages to the iterative approach. One is that the process requires far less data. The data needed to build n individual classifiers only grows linearly with n, since the individual classifiers don’t need to concern themselves with how the different features interact.
Another advantage is that the iterative approach is easy to tweak and improve. Adding targeted code to address a small subdivision of the problem is straightforward. This makes it easy to quickly deal with new corner cases — which increasingly dominate the last 20% of the problem.
By contrast, tuning a single overarching machine learning algorithm by adding new data or making changes to the code requires re-training, which can be a risky all-or-nothing proposition that offers no guarantees. As a Google paper notes, machine learning systems are complex and challenging to maintain, introducing their own forms of technical debt: Machine Learning: The High Interest Credit Card of Technical Debt.
It’s worth noting that there are instances where machine learning is indeed the best fit for a subdivision, and where it should be used. But it’s likewise true that when domain specific logic or human review are a better fit, they should instead be used. Having the flexibility to choose is a powerful advantage.
The key becomes understanding which tool is the best one for the job.
I Swear To Tell The Truth
Putting aside cost and maintenance, evaluating which technique is best for a particular subdivision is mostly a question of accuracy. Accuracy is measured by precision and recall.
These are mathematical concepts, but expressed in simple terms:
- high precision means rarely having false positives (i.e., rarely being wrong when you classify something as “X”)
- high recall means rarely having false negatives (i.e., rarely being wrong when you classify something as “not X”)
Because I work with legal technology, I like to find analogies in the law. The oath for providing sworn testimony perfectly embodies these ideas:
I swear to tell the truth, the whole truth, and nothing but the truth.
Telling “the truth” is accuracy, telling the “whole truth” without leaving anything out is high recall, and telling “nothing but the truth” without including untruths is high precision.
Thinking about the oath this way helps explain two of the main techniques witnesses use to avoid “telling the truth“:
- Limiting the information they provide by forgetting (i.e., lowering their recall)
- Limiting the information they provide by being pedantic about language (i.e., increasing their precision)
Balancing Precision And Recall
Precision and recall exhibit a tension similar to a seesaw. You can lean towards a system that never has false positives, but it will consequently have many false negatives. You can also lean towards a system that never has false negatives, but it will consequently have many false positives. The challenge is to find the right balance.
Because we’re trying to get as close to 100% accuracy as we can at Judicata, our software needs to have both high precision and high recall. We accomplish this by building two classifiers for every feature “X” that we model: one that can identify “X” with high precision, and one that can classify “Not X” with high precision.
If the first classifier can’t confidently identify an input as “X” and the second classifier can’t confidently identify that input as “Not X,” then we pass the input over to a person to review. This gets us a highly accurate system where the software does the bulk of work, and humans are only responsible for the long tail of recall.
But this is only worthwhile if the automated system has very high precision. If the automated system has low precision, then it won’t surface the right things for human review. The humans in the loop will become a significant expense without producing a worthwhile accuracy return.
The Drunk Man And The Streetlight
It’s important to note that measuring precision and recall can be much harder than they might seem. Subtle biases in how people select evaluation data can make a big difference. These are known as sampling biases, and they are usually completely innocent.
It’s therefore wise to take reported numbers with a large grain of salt.
For example, consider software intended to identify whether one case is overruling another one. (Knowing whether a case is still good law is an important piece of information for lawyers.)
It’s easy to run a classifier on sentences with the word “overrule” and measure precision and recall. But what about other words used to declare that a case is being (or has been) overruled? And what about when the language is spread across multiple sentences and paragraphs, or even cases? How do you find and evaluate that data?
The problem is well illustrated by a joke:
A policeman sees a drunk man searching for something under a streetlight and asks what the drunk has lost. He says he lost his keys and they both look under the streetlight together. After a few minutes the policeman asks if he is sure he lost them here, and the drunk replies, no, and that he lost them in the park. The policeman asks why he is searching here, and the drunk replies, “this is where the light is”.
This is a phenomenon known as the Streetlight Effect:
The streetlight effect is a type of observational bias that occurs when people are searching for something and look only where it is easiest.
I suspect the Streetlight Effect is a much larger source of error for machine learning than the researcher and developer communities realize. It’s very easy to focus on the simple situations in front of you where machine learning is doing great (especially when you want to publish a paper). It’s much more difficult to systematically look for errors and comb the dark corners of the problem space.
This is how we get, for example, software that mistakenly tags black people in photos as “Gorillas”.
The nice thing about the iterative approach is that it brings this division between easy and hard, light and dark, to the fore. By segmenting the problem into subdivisions, it’s much easier to verify that a particular subdivision is characterized by only the features that you want it to have. Counterexamples can always be cleaved off and put in a new subdivision with the classification of a new feature.
Closing Thoughts
While the advances being made in machine learning are large and real (as well as cool and exciting), relying on software alone to produce the accuracy that lawyers need is a non-starter.
Increasingly, we’re seeing that lawyers are not alone in their need for accurate and reliable software. As technology is taking over more of the world, other groups are also pushing back against error. Facebook, Google, and Twitter are getting skewered for promoting fake news. The National Transportation Safety Board is investigating how a driverless shuttle in Las Vegas was involved in an accident within one hour of beginning service. And criminal sentencing algorithms are being criticized for potential racial bias.
While a human-in-the-loop solution is not always needed, it’s a great solution to have when you need exceptionally high accuracy. The more that people recognize this paradigm, and the wider the best practices are spread, the smarter our software will ultimately be.
Editor’s Note: This article is republished with permission of the author – first published on Judicata.com